
Machine learning is used in many areas of our lives from optimizing business models to exploring black holes and predicting the spread of cancer cells.
What does machine learning look like from the inside out? What steps does the system go through before providing us with the result? Check out serokell.io to learn more about it.
Suppose we need to determine if we see a cake or pizza in front of us. In order to answer this question, we need to build an ML model.
Steps to build a machine learning solution
To build a model, you need to train it. But in order to train the model, it is necessary to collect data for training. This will be our first step.
Table of Contents
1. Data collection

The accuracy of a machine learning model greatly depends on the quality of your dataset. The data should be accurate and illustrative in case you want to get the insights that are really going to help you with problem-solving.
It is up to you whether to collect and prepare the data yourself using the company’s internal data or open-source projects or use datasets publicly available online. Google Dataset Search, Kaggle, and other resources have at their disposition a number of datasets that cover practically any area of life. However, often working with structured data is not suitable for the project. For example, if you are building a fraud-detection system for a banking institution you are going to work with large amounts of unstructured streaming data.
2. Data Preparation

Once you have collected data, it is time to prepare it. Depending on the type of machine learning models that you use, you will need different techniques of data preparation. However, the first step is to separate all information into three groups: training data, test data, and validation data. The first group is used to train the model, and the bigger the number of the samples is better. It should be 70-80% of all the data samples you have. The test data allows you to evaluate the model once you have to build your model. Sometimes data scientists also use validation sets if the results that the model shows are mixed or uncertain.
The data in the test set should not repeat the training set samples because you need to teach the computer to make decisions, not to memorize the good results.
3. Model selection
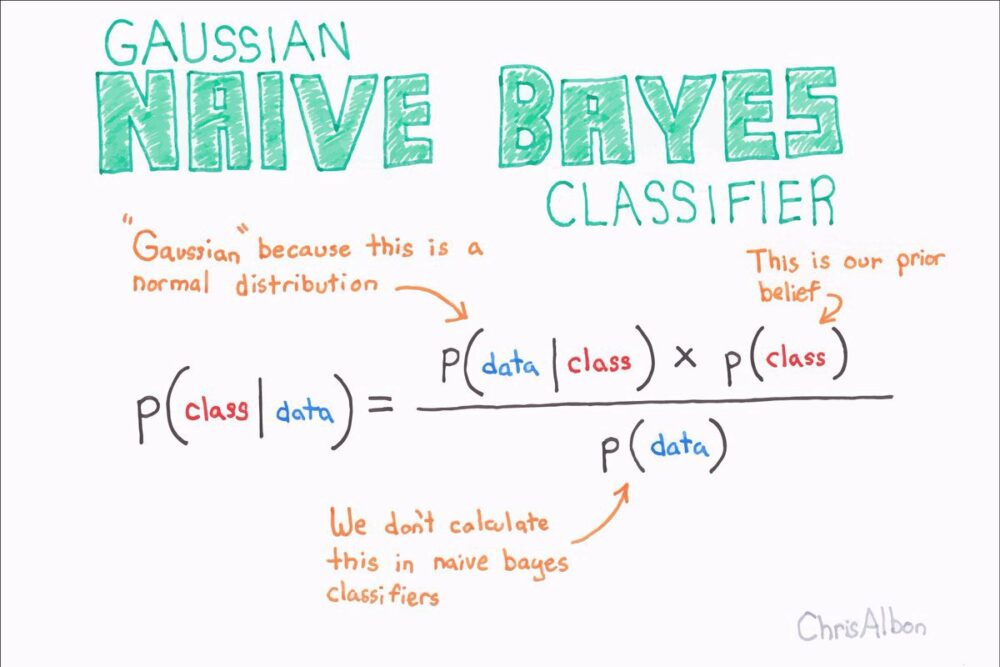
The next step is to choose the right model. Different tasks, for example, classification of customers or voice synthesis will require different algorithms. If you know how ML algorithms are classified, it will be easier for you to choose the right model.
When choosing a model, the following parameters should be considered:
Accuracy. It is not always required to get the result with maximum accuracy. In some cases, it will be appropriate to use approximate values, which can significantly reduce the processing time. Also, the accuracy depends on the amount of your data. So if you wish to build models that make accurate predictions, you will need to do a very meticulous job on data preparation.
Training time. Sometimes you need to get extremely accurate models but the higher the accuracy, the longer it takes to train them. If you are building a medical diagnosis program, spending a lot of time on tuning makes sense. However, in many situations a lower percentage of accuracy is acceptable. If you need to get the model trained as soon as possible, choose algorithms that are quick to build and train like k-NN or Naive Bayes. Later on, you will be able to think about how to improve their results.
A number of parameters. Parameters directly affect the behavior of the algorithm, for example, the number of iterations or the sensitivity to errors. Usually, the larger the number of parameters, the greater the number of attempts and errors on the way to finding the best combination.
On the other hand, a large number of parameters gives the algorithm greater flexibility and allows it to achieve higher accuracy.
4. Training

Now we will pass directly to training. Training is different for supervised, unsupervised and reinforcement learning models.
In supervised learning, you show samples to the machine that are labeled. Based on examples, the computer learns to predict the results for new data as well. A programmer serves as a teacher who corrects the mistakes of the machine when it is presented with new data.
In unsupervised learning, the training process is implicit. You input data to the models and wait until it processes it and provides some output. The model becomes more and more accurate the more data is received.
However, it is a “black box”, and there is no way to see what is the logic behind the insights.
In reinforcement learning, the environment serves as the teacher. It provides positive and negative feedback for the agent just like in real life. RL is commonly used for driverless cars where feedback teaches them not to drive into walls or strangers.
5. Evaluation
Having trained your model, you need to check whether it works well. This is where you test set steps into the game. Here you need to access whether the model manages to work with new data effectively. If it does not, or the accuracy of the model is not as high as you expected you may need to fine-tune it.
6. Fine-tuning

Fine-tuning is a necessary step if you want to improve the performance of your program. This is a trial-and-error method where you try to play with different parameters, apply a different set of methods of ensemble learning, assign different values to k-based algorithms. Then you run your model on a validation set that shows which of the algorithms is more accurate.
7. Getting predictions
Congratulations! Having completed all the steps, you now have a functional machine learning model that is able to classify data effectively and efficiently.
Conclusion

Machine learning can be used in many areas of our lives to make valuable predictions, optimize processes, and improve the quality of services. Now you know how to build your own ML model. However, if you don’t have much experience with this kind of software, it is better to address professionals.





